Cost functions
During this lesson, we'll learn how to evaluate a cost function:
- First, we'll learn about Qiskit Runtime primitives
- Define a cost function . This is a problem-specific function that defines the problem's goal for the optimizer to minimize (or maximize)
- Defining a measurement strategy with the Qiskit Runtime primitives to optimize speed versus accuracy

Primitives
All physical systems, whether classical or quantum, can exist in different states. For example, a car on a road can have a certain mass, position, speed, or acceleration that characterize its state. Similarly, quantum systems can also have different configurations or states, but they differ from classical systems in how we deal with measurements and state evolution. This leads to unique properties such as superposition and entanglement that are exclusive to quantum mechanics. Just like we can describe a car's state using physical properties like speed or acceleration, we can also describe the state of a quantum system using observables, which are mathematical objects.
In quantum mechanics, states are represented by normalized complex column vectors, or kets (), and observables are Hermitian linear operators () that act on the kets. An eigenvector () of an observable is known as an eigenstate. Measuring an observable for one of its eigenstates () will give us the corresponding eigenvalue () as readout.
If you're wondering how to measure a quantum system and what you can measure, Qiskit offers two Basic and fundamental operations or data type. Qiskit has the Sampler and Estimator primitives to serve as building blocks to easily construct complex algorithmic workloads. that can help:
Sampler: Given a quantum state , this primitive obtains the probability of each possible computational basis state.Estimator: Given a quantum observable and a state , this primitive computes the expected value of .
The Sampler primitive
The Sampler primitive calculates the probability of obtaining each possible state from the computational basis, given a quantum circuit that prepares the state . It calculates
Where is the number of qubits, and the integer representation of any possible output binary string (that is, integers base ).
The Qiskit Runtime Sampler runs the circuit multiple times on a quantum device, performing measurements on each run, and reconstructing the probability distribution from the recovered bitstrings. The more runs (or shots) it performs, the more accurate the results will be, but this requires more time and quantum resources.
However, since the number of possible outputs grows exponentially with the number of qubits (that is, ), the number of shots will need to grow exponentially as well in order to capture a dense probability distribution. Therefore, Sampler is only efficient for sparse probability distributions; where the target state must be expressible as a linear combination of the computational basis states, with the number of terms growing at most polynomially with the number of qubits:
The Sampler can also be configured to retrieve probabilities from a subsection of the circuit, representing a subset of the total possible states.
The Estimator primitive
The Estimator primitive calculates the expectation value of an observable for a quantum state ; where the observable probabilities can be expressed as , being the eigenstates of the observable . The expectation value is then defined as the average of all possible outcomes (that is, the eigenvalues of the observable) of a measurement of the state , weighted by the corresponding probabilities:
However, calculating the expectation value of an observable is not always possible, as we often don't know its eigenbasis. The Qiskit Runtime Estimator uses a complex algebraic process to estimate the expectation value on a real quantum device by breaking down the observable into a combination of other observables whose eigenbasis we do know.
In simpler terms, Estimator breaks down any observable that it doesn't know how to measure into simpler, measurable observables called Set of matrices commonly used in quantum computing to represent and manipulate quantum states, consisting of the identity matrix and the three Pauli matrices (X, Y, and Z)..
Any operator can be expressed as a combination of Pauli operators.
such that
where is the number of qubits, for (that is, integers base ), and .
After performing this decomposition, Estimator derives a new circuit for each observable (from the original circuit), to effectively diagonalize the Pauli observable in the computational basis and measure it. We can easily measure Pauli observables because we know ahead of time, which is not the case generally for other observables.
For each , the Estimator runs the corresponding circuit on a quantum device multiple times, measures the output state in the computational basis, and calculates the probability of obtaining each possible output . It then looks for the eigenvalue of corresponding to each output , multiplies by , and adds all the results together to obtain the expected value of the observable for the given state .
Since calculating the expectation value of Paulis is impractical (that is, exponentially growing), Estimator can only be efficient when a large amount of are zero (that is, sparse Pauli decomposition instead of dense). Formally we say that, for this computation to be efficiently solvable, the number of non-zero terms has to grow at most polynomially with the number of qubits :
The reader may notice the implicit assumption that probability The process of taking several measurements of one or several things. also needs to be efficient as explained for Sampler, which means
Guided example to calculate expectation values
Let's assume the single-qubit state , and observable
with the following theoretical expectation value
Since we do not know how to measure this observable, we cannot compute its expectation value directly, and we need to re-express it as . Which can be shown to evaluate to the same result by virtue of noting that , and .
Let see how to compute and directly. Since and do not commute (that is, they don't share the same eigenbasis), they cannot be measured simultaneously, therefore we need the auxiliary circuits:
from qiskit import QuantumCircuit
from qiskit.quantum_info import SparsePauliOp
# The following code will work for any other initial single-qubit state and observable
original_circuit = QuantumCircuit(1)
original_circuit.h(0)
H = SparsePauliOp(["X", "Z"], [2, -1])
aux_circuits = []
for pauli in H.paulis:
aux_circ = original_circuit.copy()
aux_circ.barrier()
if str(pauli) == "X":
aux_circ.h(0)
elif str(pauli) == "Y":
aux_circ.sdg(0)
aux_circ.h(0)
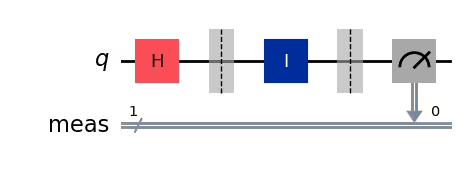
else:
aux_circ.id(0)
aux_circ.measure_all()
aux_circuits.append(aux_circ)
original_circuit.draw("mpl")Output:
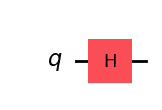
# Auxiliary circuit for X
aux_circuits[0].draw("mpl")Output:
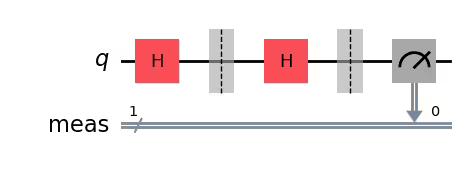
# Auxiliary circuit for Z
aux_circuits[1].draw("mpl")Output:
We can now carry out the computation manually using Sampler and check the results on Estimator:
from qiskit.primitives import StatevectorSampler, StatevectorEstimator
from qiskit.result import QuasiDistribution
import numpy as np
## SAMPLER
shots = 10000
sampler = StatevectorSampler()
job = sampler.run(aux_circuits, shots=shots)
# Run the sampler job and step through results
expvals = []
for index, pauli in enumerate(H.paulis):
data_pub = job.result()[index].data
bitstrings = data_pub.meas.get_bitstrings()
counts = data_pub.meas.get_counts()
quasi_dist = QuasiDistribution(
{outcome: freq / shots for outcome, freq in counts.items()}
)
# Use the probabilities and known eigenvalues of Pauli operators to estimate
# the expectation value.
val = 0
if str(pauli) == "X":
val += -1 * quasi_dist.get(1, 0)
val += 1 * quasi_dist.get(0, 0)
if str(pauli) == "Y":
val += -1 * quasi_dist.get(1, 0)
val += 1 * quasi_dist.get(0, 0)
if str(pauli) == "Z":
val += 1 * quasi_dist.get(0, 0)
val += -1 * quasi_dist.get(1, 0)
expvals.append(val)
# Print expectation values
print("Sampler results:")
for pauli, expval in zip(H.paulis, expvals):
print(f" >> Expected value of {str(pauli)}: {expval:.5f}")
total_expval = np.sum(H.coeffs * expvals).real
print(f" >> Total expected value: {total_expval:.5f}")
# Use estimator for comparison
observables = [
*H.paulis,
H,
] # Note: run for individual Paulis as well as full observable H
estimator = StatevectorEstimator()
job = estimator.run([(original_circuit, observables)])
estimator_expvals = job.result()[0].data.evs
# Print results
print("Estimator results:")
for obs, expval in zip(observables, estimator_expvals):
if obs is not H:
print(f" >> Expected value of {str(obs)}: {expval:.5f}")
else:
print(f" >> Total expected value: {expval:.5f}")Output:
Sampler results:
>> Expected value of X: 1.00000
>> Expected value of Z: 0.00420
>> Total expected value: 1.99580
Estimator results:
>> Expected value of X: 1.00000
>> Expected value of Z: 0.00000
>> Total expected value: 2.00000
Mathematical rigor (optional)
Expressing with respect to the basis of eigenstates of , , it follows:
Since we do not know the eigenvalues or eigenstates of the target observable , first we need to consider its diagonalization. Given that is A Hermitian is a square matrix that is equal to its own conjugate transpose, or a linear operator that is self-adjoint., there exists a unitary transformation such that where is the diagonal eigenvalue matrix, so if , and .
This implies that the expected value can be rewritten as:
Given that if a system is in the state the probability of measuring is , the above expected value can be expressed as:
It is very important to note that the probabilities are taken from the state instead of . This is why the matrix is absolutely necessary.
You might be wondering how to obtain the matrix and the eigenvalues . If you already had the eigenvalues, then there would be no need to use a quantum computer since the goal of variational algorithms is to find these eigenvalues of .
Fortunately, there is a way around that: any matrix can be written as a linear combination of tensor products of Pauli matrices and identities, all of which are both hermitian and unitary with known and . This is what Runtime's Estimator does internally by decomposing any Operator object into a SparsePauliOp.
Here are the Operators that can be used:
So let's rewrite with respect to the Paulis and identities:
where for (that is, base ), and :
where and , such that:
Cost functions
In general, cost functions are used to describe the goal of a problem and how well a trial state is performing with respect to that goal. This definition can be applied to various examples in chemistry, machine learning, finance, optimization, and so on.
Let's consider a simple example of finding the ground state of a system. Our objective is to minimize the expectation value of the observable representing energy (Hamiltonian ):
We can use the Estimator to evaluate the expectation value and pass this value to an optimizer to minimize. If the optimization is successful, it will return a set of optimal parameter values , from which we will be able to construct the proposed solution state and compute the observed expectation value as .
Notice how we will only be able to minimize the cost function for the limited set of states that we are considering. This leads us to two separate possibilities:
- Our ansatz does not define the solution state across the search space: If this is the case, our optimizer will never find the solution, and we need to experiment with other ansatzes that might be able to represent our search space more accurately.
- Our optimizer is unable to find this valid solution: Optimization can be globally defined and locally defined. We'll explore what this means in the later section.
All in all, we will be performing a classical optimization loop but relying on the evaluation of the cost function to a quantum computer. From this perspective, one could think of the optimization as a purely classical endeavor where we call some A hypothetical device or software component that performs a specific function, but the internal workings of which are unknown. A user is only aware of the inputs and outputs of the black box, and has no knowledge of how the black box processes the inputs to produce the outputs. each time the optimizer needs to evaluate the cost function.
def cost_func_vqe(params, circuit, hamiltonian, estimator):
"""Return estimate of energy from estimator
Parameters:
params (ndarray): Array of ansatz parameters
ansatz (QuantumCircuit): Parameterized ansatz circuit
hamiltonian (SparsePauliOp): Operator representation of Hamiltonian
estimator (Estimator): Estimator primitive instance
Returns:
float: Energy estimate
"""
pub = (circuit, hamiltonian, params)
cost = estimator.run([pub]).result()[0].data.evs
return costfrom qiskit.circuit.library import TwoLocal
observable = SparsePauliOp.from_list([("XX", 1), ("YY", -3)])
reference_circuit = QuantumCircuit(2)
reference_circuit.x(0)
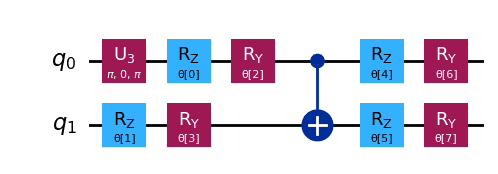
variational_form = TwoLocal(
2,
rotation_blocks=["rz", "ry"],
entanglement_blocks="cx",
entanglement="linear",
reps=1,
)
ansatz = reference_circuit.compose(variational_form)
theta_list = (2 * np.pi * np.random.rand(1, 8)).tolist()
ansatz.decompose().draw("mpl")Output:
We will first carry this out using a simulator: the StatevectorEstimator. This is usually advisable for debugging, but we will immediately follow the debugging run with a calculation on real quantum hardware. Increasingly, problems of interest are no longer classically simulable without state-of-the-art supercomputing facilities.
estimator = StatevectorEstimator()
cost = cost_func_vqe(theta_list, ansatz, observable, estimator)
print(cost)Output:
[-0.58744589]
We will now proceed with running on a real quantum computer. Note the syntax changes. The steps involving the pass_manager will be discussed further in the next example. One step of particular importance in variational algorithms is the use of a Qiskit Runtime session. Starting a session allows you to run multiple iterations of a variational algorithm without waiting in a new queue each time parameters are updated. This is important if queue times are long and/or many iterations are needed. Only partners in the IBM Quantum® Network can use Runtime sessions. If you do not have access to sessions, you can reduce the number of iterations you submit at a given time, and save the most recent parameters for use in future runs. If you submit too many iterations or encounter queue times that are too long, you may encounter error code 1217, which refers to long delays between job submissions.
# Estimated usage: < 1 min. Benchmarked at 7 seconds on an Eagle processor
# Load necessary packages:
from qiskit_ibm_runtime import (
QiskitRuntimeService,
Session,
EstimatorOptions,
EstimatorV2 as Estimator,
)
from qiskit.transpiler.preset_passmanagers import generate_preset_pass_manager
# Select the least busy backend:
service = QiskitRuntimeService()
backend = service.least_busy(
operational=True, min_num_qubits=ansatz.num_qubits, simulator=False
)
# Or get a specific backend:
# backend = service.backend("ibm_brisbane")
# Use a pass manager to transpile the circuit and observable for the specific backend being used:
pm = generate_preset_pass_manager(backend=backend, optimization_level=1)
isa_ansatz = pm.run(ansatz)
isa_observable = observable.apply_layout(layout=isa_ansatz.layout)
# Set estimator options
estimator_options = EstimatorOptions(resilience_level=1, default_shots=10_000)
# Open a Runtime session:
with Session(backend=backend) as session:
estimator = Estimator(mode=session, options=estimator_options)
cost = cost_func_vqe(theta_list, isa_ansatz, isa_observable, estimator)
session.close()
print(cost)Note that the values obtained from the two calculations above are very similar. Techniques for improving results will be discussed further below.
Example mapping to non-physical systems
The maximum cut (max-cut) problem is a combinatorial optimization problem that involves dividing the vertices of a graph into two disjoint sets such that the number of edges between the two sets is maximized. More formally, given an undirected graph , where is the set of vertices and is the set of edges, the max-cut problem asks to partition the vertices into two disjoint subsets, and , such that the number of edges with one endpoint in and the other in is maximized.
We can apply max-cut to solve a various problems including: clustering, network design, phase transitions, and so on. We'll start by creating a problem graph:
import rustworkx as rx
from rustworkx.visualization import mpl_draw
n = 4
G = rx.PyGraph()
G.add_nodes_from(range(n))
# The edge syntax is (start, end, weight)
edges = [(0, 1, 1.0), (0, 2, 1.0), (0, 3, 1.0), (1, 2, 1.0), (2, 3, 1.0)]
G.add_edges_from(edges)
mpl_draw(
G, pos=rx.shell_layout(G), with_labels=True, edge_labels=str, node_color="#1192E8"
)Output:
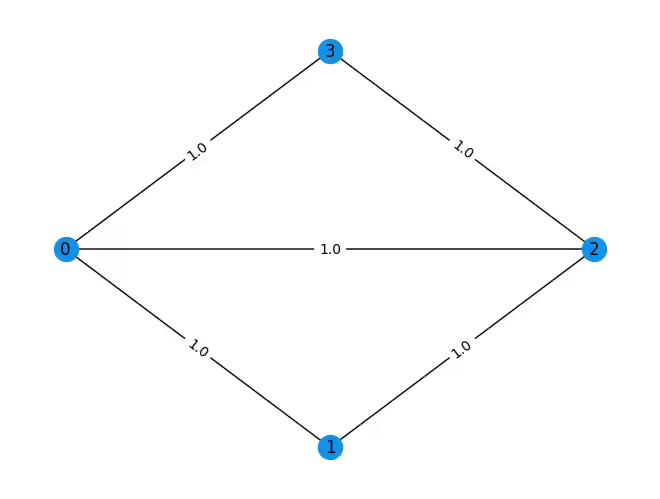
This problem can be expressed as a binary optimization problem. For each node , where is the number of nodes of the graph (in this case ), we will consider the binary variable . This variable will have the value if node is one of the groups that we'll label and if it's in the other group, that we'll label as . We will also denote as (element of the adjacency matrix ) the weight of the edge that goes from node to node . Because the graph is undirected, . Then we can formulate our problem as maximizing the following cost function:
To solve this problem with a quantum computer, we are going to express the cost function as the expected value of an observable. However, the observables that Qiskit admits natively consist of Pauli operators, that have eigenvalues and instead of and . That's why we are going to make the following change of variable:
Where . We can use the adjacency matrix to comfortably access the weights of all the edge. This will be used to obtain our cost function:
This implies that:
So the new cost function we want to maximize is:
Moreover, the natural tendency of a quantum computer is to find minima (usually the lowest energy) instead of maxima so instead of maximizing we are going to minimize:
Now that we have a cost function to minimize whose variables can have the values and , we can make the following analogy with the Pauli :
In other words, the variable will be equivalent to a gate acting on qubit . Moreover:
Then the observable we are going to consider is:
to which we will have to add the independent term afterwards:
The operator is a linear combination of terms with Z operators on nodes connected by an edge (recall that the 0th qubit is farthest right): . Once the operator is constructed, the ansatz for the QAOA algorithm can easily be built by using the QAOAAnsatz circuit from the Qiskit circuit library.
from qiskit.circuit.library import QAOAAnsatz
from qiskit.quantum_info import SparsePauliOp
hamiltonian = SparsePauliOp.from_list(
[("IIZZ", 1), ("IZIZ", 1), ("IZZI", 1), ("ZIIZ", 1), ("ZZII", 1)]
)
ansatz = QAOAAnsatz(hamiltonian, reps=2)
# Draw
ansatz.decompose(reps=3).draw("mpl")Output:
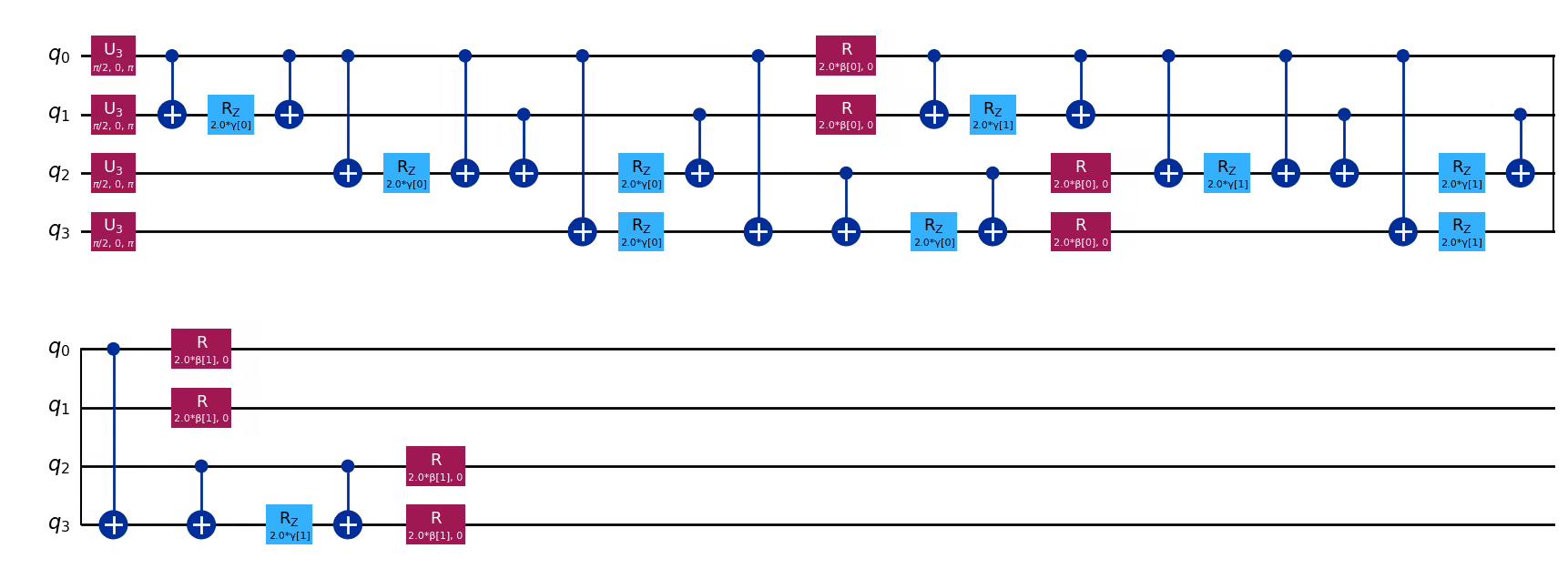
# Sum the weights, and divide by 2
offset = -sum(edge[2] for edge in edges) / 2
print(f"""Offset: {offset}""")Output:
Offset: -2.5
With the Runtime Estimator directly taking a Hamiltonian and parameterized ansatz, and returning the necessary energy, The cost function for a QAOA instance is quite simple:
def cost_func(params, ansatz, hamiltonian, estimator):
"""Return estimate of energy from estimator
Parameters:
params (ndarray): Array of ansatz parameters
ansatz (QuantumCircuit): Parameterized ansatz circuit
hamiltonian (SparsePauliOp): Operator representation of Hamiltonian
estimator (Estimator): Estimator primitive instance
Returns:
float: Energy estimate
"""
pub = (ansatz, hamiltonian, params)
cost = estimator.run([pub]).result()[0].data.evs
# cost = estimator.run(ansatz, hamiltonian, parameter_values=params).result().values[0]
return costimport numpy as np
x0 = 2 * np.pi * np.random.rand(ansatz.num_parameters)
estimator = StatevectorEstimator()
cost = cost_func_vqe(x0, ansatz, hamiltonian, estimator)
print(cost)Output:
1.473098768180865
# Estimated usage: < 1 min, benchmarked at 6 seconds on ibm_osaka, 5-23-24
# Load some necessary packages:
from qiskit_ibm_runtime import QiskitRuntimeService
from qiskit_ibm_runtime import Session, EstimatorV2 as Estimator
# Select the least busy backend:
backend = service.least_busy(
operational=True, min_num_qubits=ansatz.num_qubits, simulator=False
)
# Or get a specific backend:
# backend = service.backend("ibm_brisbane")
# Use a pass manager to transpile the circuit and observable for the specific backend being used:
pm = generate_preset_pass_manager(backend=backend, optimization_level=1)
isa_ansatz = pm.run(ansatz)
isa_hamiltonian = hamiltonian.apply_layout(layout=isa_ansatz.layout)
# Set estimator options
estimator_options = EstimatorOptions(resilience_level=1, default_shots=10_000)
# Open a Runtime session:
with Session(backend=backend) as session:
estimator = Estimator(mode=session, options=estimator_options)
cost = cost_func_vqe(x0, isa_ansatz, isa_hamiltonian, estimator)
# Close session after done
session.close()
print(cost)Output:
1.1120776913677988
We will revisit this example in Applications to explore how to leverage an optimizer to iterate through the search space. Generally speaking, this includes:
- Leveraging an optimizer to find optimal parameters
- Binding optimal parameters to the ansatz to find the eigenvalues
- Translating the eigenvalues to our problem definition
Measurement strategy: speed versus accuracy
As mentioned, we are using a noisy quantum computer as a black-box oracle, where noise can make the retrieved values non-deterministic, leading to random fluctuations which, in turn, will harm — or even completely prevent — convergence of certain optimizers to a proposed solution. This is a general problem that we must address as we incrementally explore quantum utility and progress towards quantum advantage:

We can use Qiskit Runtime Primitive's error suppression and error mitigation options to address noise and maximize the utility of today's quantum computers.
Error Suppression
Error suppression refers to techniques used to optimize and transform a circuit during compilation in order to minimize errors. This is a basic error handling technique that usually results in some classical pre-processing Extra costs introduced by new techniques, relative to a base implementation. to the overall runtime. The overhead includes transpiling circuits to run on quantum hardware by:
- Expressing the circuit using the native gates available on a quantum system
- Mapping the virtual qubits to physical qubits
- Adding SWAPs based on connectivity requirements
- Optimizing 1Q and 2Q gates
- Adding dynamical decoupling to idle qubits to prevent the effects of decoherence.
Primitives allow for the use of error suppression techniques by setting the optimization_level option and selecting advanced transpilation options. In a later course, we will delve into different circuit construction methods to improve results, but for most cases, we recommend setting optimization_level=3.
We will visualize the value of increasing optimization in the transpilation process by looking at an example circuit with a simple ideal behavior.
from qiskit.circuit import Parameter, QuantumCircuit
from qiskit.quantum_info import SparsePauliOp
theta = Parameter("theta")
qc = QuantumCircuit(2)
qc.x(1)
qc.h(0)
qc.cp(theta, 0, 1)
qc.h(0)
observables = SparsePauliOp.from_list([("ZZ", 1)])
qc.draw("mpl")Output:
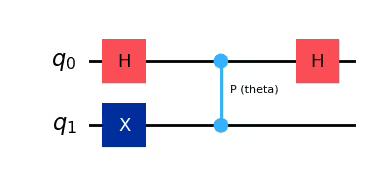
The circuit above can yield sinusoidal expectation values of the observable given, provided we insert phases spanning an appropriate interval, such as .
## Setup phases
import numpy as np
phases = np.linspace(0, 2 * np.pi, 50)
# phases need to be expressed as a list of lists in order to work
individual_phases = [[phase] for phase in phases]We can use a simulator to show the usefulness of an optimized transpilation. We will return below to using real hardware to demonstrate the usefulness of error mitigation. We will use QiskitRuntimeService to get a real backend (in this case, ibm_brisbane), and use AerSimulator to simulate that backend, including its noise behavior.
from qiskit_ibm_runtime import QiskitRuntimeService
from qiskit_aer import AerSimulator
# get a real backend from the runtime service
service = QiskitRuntimeService()
backend = service.backend("ibm_brisbane")
# generate a simulator that mimics the real quantum system with the latest calibration results
backend_sim = AerSimulator.from_backend(backend)We can now use a pass manager to transpile the circuit into the "instruction set architecture" or ISA of the backend. This is a new requirement in Qiskit Runtime: all circuits submitted to a backend must conform to the constraints of the backend’s target, meaning they must be written in terms of the backend's ISA — that is, the set of instructions the device can understand and execute. These target constraints are defined by factors like the device’s native basis gates, its qubit connectivity, and - when relevant - its pulse and other instruction timing specifications.
Note that in the present case, we will do this twice: once with optimization_level = 0, and once with it set to 3. Each time we will use the Estimator primitive to estimate the expectation values of the observable at different values of phase.
# Import estimator and specify that we are using the simulated backend:
from qiskit_ibm_runtime import EstimatorV2 as Estimator
estimator = Estimator(mode=backend_sim)
circuit = qc# Use a pass manager to transpile the circuit and observable for the backend being simulated.
# Start with no optimization:
from qiskit.transpiler.preset_passmanagers import generate_preset_pass_manager
pm = generate_preset_pass_manager(backend=backend_sim, optimization_level=0)
isa_circuit = pm.run(circuit)
isa_observables = observables.apply_layout(layout=isa_circuit.layout)
noisy_exp_values = []
pub = (isa_circuit, isa_observables, [individual_phases])
cost = estimator.run([pub]).result()[0].data.evs
noisy_exp_values = cost[0]
# Repeat above steps, but now with optimization = 3:
exp_values_with_opt_es = []
pm = generate_preset_pass_manager(backend=backend_sim, optimization_level=3)
isa_circuit = pm.run(circuit)
isa_observables = observables.apply_layout(layout=isa_circuit.layout)
pub = (isa_circuit, isa_observables, [individual_phases])
cost = estimator.run([pub]).result()[0].data.evs
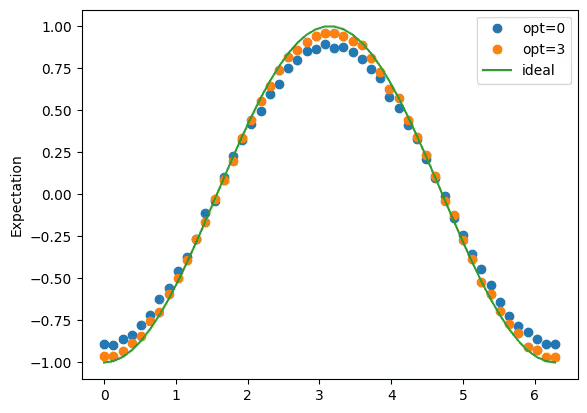
exp_values_with_opt_es = cost[0]Finally, we can plot the results, and we see that the precision of the calculation was fairly good even without optimization, but it definitely improved by increasing optimization to level 3. Note that in deeper, more complicated circuits, the difference between optimization levels of 0 and 3 are likely to be more significant. This is a very simple circuit used as a toy model.
import matplotlib.pyplot as plt
plt.plot(phases, noisy_exp_values, "o", label="opt=0")
plt.plot(phases, exp_values_with_opt_es, "o", label="opt=3")
plt.plot(phases, 2 * np.sin(phases / 2) ** 2 - 1, label="ideal")
plt.ylabel("Expectation")
plt.legend()
plt.show()Output:
Error Mitigation
Error mitigation refers to techniques that allow users to reduce circuit errors by modeling the device noise at the time of execution. Typically, this results in quantum pre-processing overhead related to model training and classical post-processing overhead to mitigate errors in the raw results by using the generated model.
The Qiskit Runtime primitive's resilience_level option specifies the amount of resilience to build against errors. Higher levels generate more accurate results at the expense of longer processing times due to quantum sampling overhead. Resilience levels can be used to configure the trade-off between cost and accuracy when applying error mitigation to your primitive query.
When implementing any error mitigation technique, we expect the A systematic drift in the measured quantities, usually caused by errors. in our results to be reduced with respect to the previous, unmitigated bias. In some cases, the bias may even disappear. However, this comes at a cost. As we reduce the bias in our estimated quantities, the statistical variability will increase (that is, variance), which we can account for by further increasing the number of shots per circuit in our sampling process. This will introduce overhead beyond that needed to reduce the bias, so it is not done by default. We can easily opt-in to this behavior by adjusting the number of shots per circuit in options.executions.shots, as shown in the example below.

For this course, we will explore these error mitigation models at a high level to illustrate the error mitigation that Qiskit Runtime primitives can perform without requiring full implementation details.
Twirled readout error extinction (T-REx)
Twirled readout error extinction (T-REx) uses a technique known as Pauli twirling to reduce the noise introduced during the process of quantum measurement. This technique assumes no specific form of noise, which makes it very general and effective.
Overall workflow:
- Acquire data for the zero state with randomized bit flips (Pauli X before measurement)
- Acquire data for the desired (noisy) state with randomized bit flips (Pauli X before measurement)
- Compute the special function for each data set, and divide.

We can set this with options.resilience_level = 1, demonstrated in the example below.
Zero noise extrapolation
Zero noise extrapolation (ZNE) works by first amplifying the noise in the circuit that is preparing the desired quantum state, obtaining measurements for several different levels of noise, and using those measurements to infer the noiseless result.
Overall workflow:
- Amplify circuit noise for several noise factors
- Run every noise amplified circuit
- Extrapolate back to the zero noise limit

We can set this with options.resilience_level = 2. We can optimize this further by exploring a variety of noise_factors, noise_amplifiers, and extrapolators, but this is outside the scope of this course. We encourage you to experiment with these options as described here.
Each method comes with its own associated overhead: a trade-off between the number of quantum computations needed (time) and the accuracy of our results:
Using Qiskit Runtime's mitigation and suppression options
Here's how to calculate an expectation value while using error mitigation and suppression in Qiskit Runtime. We can make use of precisely the same circuit and observable as before, but this time keeping the optimization level fixed at level 2, and now tuning the resilience or the error mitigation technique(s) being used. This error mitigation process occurs multiple times throughout an optimization loop.
We perform this part on real hardware, since error mitigation is not available on simulators.
# Estimated usage: 8 minutes, benchmarked on an Eagle processor, 5-23-24
from qiskit_ibm_runtime import QiskitRuntimeService
from qiskit_ibm_runtime import (
Session,
EstimatorOptions,
EstimatorV2 as Estimator,
)
# We select the least busy backend
# Select the least busy backend
# backend = service.least_busy(
# operational=True, min_num_qubits=ansatz.num_qubits, simulator=False
# )
# Or use a specific backend
backend = service.backend("ibm_brisbane")
# Initialize some variables to save the results from different runs:
exp_values_with_em0_es = []
exp_values_with_em1_es = []
exp_values_with_em2_es = []
# Use a pass manager to optimize the circuit and observables for the backend chosen:
pm = generate_preset_pass_manager(backend=backend, optimization_level=2)
isa_circuit = pm.run(circuit)
isa_observables = observables.apply_layout(layout=isa_circuit.layout)
# Open a session and run with no error mitigation:
estimator_options = EstimatorOptions(resilience_level=0, default_shots=10_000)
with Session(backend=backend) as session:
estimator = Estimator(mode=session, options=estimator_options)
pub = (isa_circuit, isa_observables, [individual_phases])
cost = estimator.run([pub]).result()[0].data.evs
session.close()
exp_values_with_em0_es = cost[0]
# Open a session and run with resilience = 1:
estimator_options = EstimatorOptions(resilience_level=1, default_shots=10_000)
with Session(backend=backend) as session:
estimator = Estimator(mode=session, options=estimator_options)
pub = (isa_circuit, isa_observables, [individual_phases])
cost = estimator.run([pub]).result()[0].data.evs
session.close()
exp_values_with_em1_es = cost[0]
# Open a session and run with resilience = 2:
estimator_options = EstimatorOptions(resilience_level=2, default_shots=10_000)
with Session(backend=backend) as session:
estimator = Estimator(mode=session, options=estimator_options)
pub = (isa_circuit, isa_observables, [individual_phases])
cost = estimator.run([pub]).result()[0].data.evs
session.close()
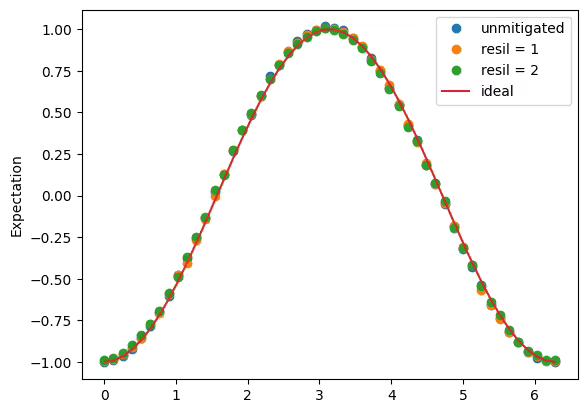
exp_values_with_em2_es = cost[0]As before, we can plot the resulting expectation values as a function of phase angle for the three levels of error mitigation used. With great difficulty, one can see that error mitigation improves the results slightly. Again, this effect is much more pronounced in deeper, more complicated circuits.
import matplotlib.pyplot as plt
plt.plot(phases, exp_values_with_em0_es, "o", label="unmitigated")
plt.plot(phases, exp_values_with_em1_es, "o", label="resil = 1")
plt.plot(phases, exp_values_with_em2_es, "o", label="resil = 2")
plt.plot(phases, 2 * np.sin(phases / 2) ** 2 - 1, label="ideal")
plt.ylabel("Expectation")
plt.legend()
plt.show()Output:
Summary
With this lesson, you learned how to create a cost function:
- Create a cost function
- How to leverage Qiskit Runtime primitives to mitigate and suppression noise
- How to define a measurement strategy to optimize speed vs accuracy
Here's our high-level variational workload:

Our cost function runs during every iteration of the optimization loop. The next lesson will explore how the classical optimizer uses our cost function evaluation to select new parameters.
import qiskit
import qiskit_ibm_runtime
print(qiskit.version.get_version_info())
print(qiskit_ibm_runtime.version.get_version_info())Output:
1.1.0
0.23.0