Noyaux quantiques
Introduction aux noyaux quantiques
La "méthode du noyau quantique" fait référence à toute méthode qui utilise des ordinateurs quantiques pour estimer un noyau. Dans ce contexte, le terme "noyau" fait référence à la matrice du noyau ou à ses entrées individuelles. Rappelons qu'une cartographie des caractéristiques est une cartographie de à où habituellement et où l'objectif de cette cartographie est de rendre les catégories de données séparables par un hyperplan. La fonction noyau prend comme arguments des vecteurs dans l'espace cartographié et renvoie leur produit intérieur, c'est-à-dire avec . Classiquement, nous nous intéressons aux cartes de caractéristiques pour lesquelles la fonction noyau est facile à évaluer. Il s'agit souvent de trouver une fonction noyau pour laquelle le produit intérieur dans l'espace cartographié peut être écrit en termes de vecteurs de données originaux, sans avoir à construire et . Dans la méthode des noyaux quantiques, la cartographie des caractéristiques est réalisée par un circuit quantique et le noyau est estimé à l'aide de mesures sur ce circuit et des probabilités de mesure relatives.
Dans cette leçon, nous examinerons les profondeurs des circuits de codage précodés qui utilisent un enchevêtrement substantiel et nous les comparerons aux profondeurs des circuits que nous codons à la main. Il ne s'agit pas de préconiser une méthode plutôt qu'une autre. Il se peut que les circuits précodés soient trop profonds et que l'enchevêtrement dans le circuit personnalisé soit insuffisant pour être utile. Encore une fois, ces informations ne sont présentées que pour vous permettre d'explorer le sujet.
Avant d'examiner en détail l'estimation d'une matrice de noyau, décrivons le processus en utilisant le langage des modèles Qiskit.
Étape 1 : Mettre en correspondance les entrées classiques avec un problème quantique
- Entrée : Ensemble de données d'apprentissage
- Sortie : Circuit abstrait pour le calcul d'une entrée de la matrice du noyau
Étant donné l'ensemble de données, le point de départ consiste à encoder les données dans un circuit quantique. En d'autres termes, nous devons cartographier nos données dans l'espace de Hilbert des états de notre ordinateur quantique. Pour ce faire, nous construisons un circuit dépendant des données. Il existe de nombreuses façons de procéder, et la leçon précédente a présenté un certain nombre d'options. Vous pouvez construire votre propre circuit pour encoder vos données, ou utiliser une carte préétablie comme zz_feature_map. Dans cette leçon, nous ferons les deux.
Notez que pour calculer un seul élément de la matrice du noyau, nous devons encoder deux points différents, afin de pouvoir estimer leur produit intérieur. Un flux de travail complet de noyau quantique impliquera bien sûr de nombreux produits intérieurs entre les vecteurs de données mappés, ainsi que des méthodes classiques d'apprentissage automatique. Mais l'étape centrale qui est itérée est l'estimation d'un seul élément de la matrice du noyau. Pour ce faire, nous sélectionnons un circuit quantique dépendant des données et mettons en correspondance deux vecteurs de données dans l'espace des caractéristiques.
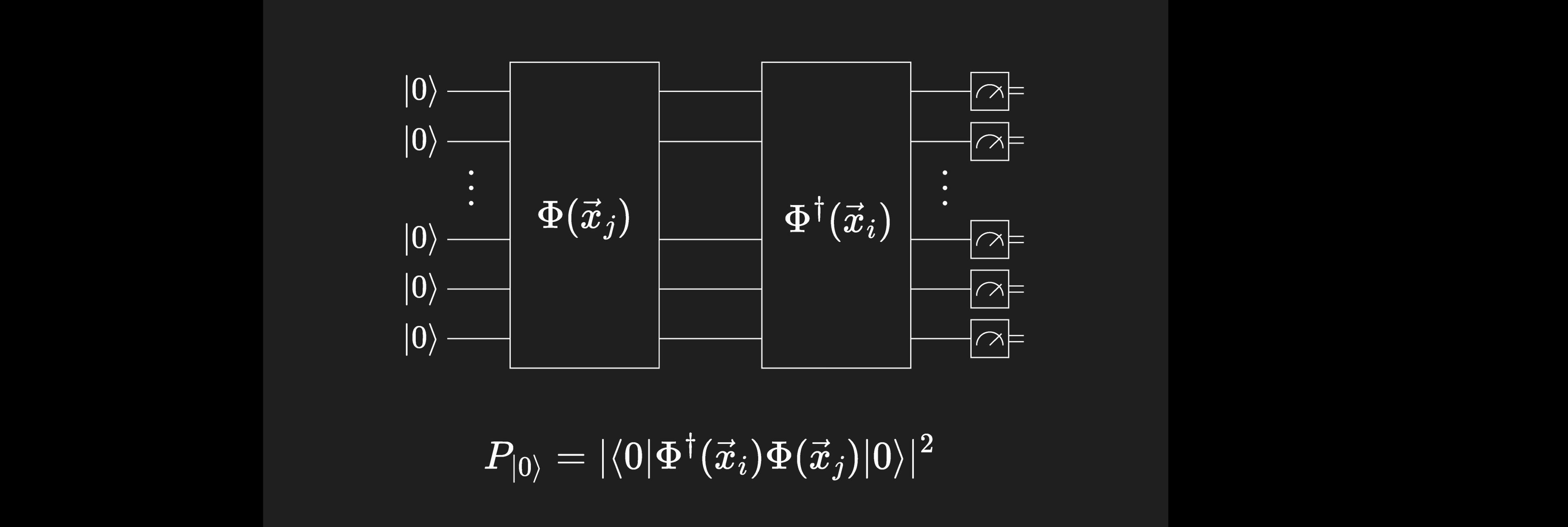
Pour générer une matrice de noyau, nous sommes particulièrement intéressés par la probabilité de mesurer l'état , dans lequel tous les qubits sont dans l'état . Pour s'en convaincre, considérons que le circuit responsable du codage et de la mise en correspondance d'un vecteur de données peut être écrit sous la forme , et que celui responsable du codage et de la mise en correspondance est , et désignons les états mis en correspondance par les termes suivants
Ces états correspondent au mappage des données dans des dimensions supérieures, de sorte que l'entrée du noyau souhaitée est le produit intérieur
Si nous opérons sur l'état initial par défaut avec les deux circuits et , la probabilité de mesurer ensuite l'état est de
C'est exactement la valeur que nous voulons (jusqu'à ). La couche de mesure de notre circuit renvoie des probabilités de mesure (ou des "quasi-probabilités", si certaines méthodes d'atténuation des erreurs sont utilisées). La probabilité qui nous intéresse est celle de l'état zéro, .
Étape 2 : Optimiser le problème pour l'exécution quantique
- Entrée : Circuit abstrait, non optimisé pour un backend particulier
- Résultat : Circuit cible et observable, optimisés pour la QPU sélectionnée
Dans cette étape, nous utiliserons la fonction generate_preset_pass_manager de Qiskit pour spécifier une routine d'optimisation pour notre circuit par rapport à l'ordinateur quantique réel sur lequel nous prévoyons de réaliser l'expérience. Nous avons choisi optimization_level=3 , ce qui signifie que nous utiliserons le gestionnaire de passes prédéfini qui offre le niveau d'optimisation le plus élevé. Dans ce contexte, le terme "optimisation" désigne l'optimisation de la mise en œuvre du circuit sur un véritable ordinateur quantique. Cela inclut des considérations telles que la sélection de qubits physiques correspondant aux qubits du circuit quantique abstrait qui minimisera la profondeur de grille, ou la sélection de qubits physiques avec les taux d'erreur disponibles les plus bas. Ceci n'est pas directement lié à l'optimisation du problème d'apprentissage automatique (comme dans les optimiseurs classiques tels que COBYLA).
Selon la manière dont vous mettez en œuvre l'étape 2, vous devrez peut-être optimiser le circuit plus d'une fois, car chaque paire de points impliqués dans un élément de matrice produit un circuit différent à mesurer.
Étape 3 : Exécuter à l'aide des primitives d' Qiskit Runtime
- Entrée : Circuit cible
- Résultat : Distribution de probabilité
Utilisez la primitive Sampler de Qiskit Runtime pour reconstruire une distribution de probabilité des états obtenus à partir de l'échantillonnage du circuit. Notez qu'il s'agit d'une "distribution de quasi-probabilité", un terme qui s'applique lorsque le bruit est un problème et lorsque des étapes supplémentaires sont introduites, comme dans le cas de l'atténuation des erreurs. Dans ce cas, la somme de toutes les probabilités peut ne pas être exactement égale à 1, d'où le terme de "quasi-probabilité".
Étape 4 : Post-traitement, renvoi du résultat dans un format classique
- Entrée : Distribution de probabilité
- Sortie : Un seul élément de la matrice du noyau, ou une matrice du noyau en cas de répétition
Calculer la probabilité de mesurer sur le circuit quantique et remplir la matrice du noyau à la position correspondant aux deux vecteurs de données utilisés. Pour remplir toute la matrice du noyau, nous devons réaliser une expérience quantique pour chaque entrée. Une fois que nous disposons d'une matrice noyau, nous pouvons l'utiliser dans de nombreux algorithmes classiques d'apprentissage automatique qui acceptent pre-calculated kernels. Par exemple : qml_svc = SVC(kernel="precomputed"). Nous pouvons ensuite utiliser les flux de travail classiques pour appliquer notre modèle à nos données de test et obtenir un score de précision. En fonction de la satisfaction que nous procure notre score de précision, nous pourrons être amenés à revoir certains aspects de notre calcul, tels que notre carte des caractéristiques.
Plan de cours
Dans cette leçon, nous effectuerons ces étapes de plusieurs manières afin d'utiliser au mieux votre temps sur de véritables ordinateurs quantiques. Nous appliquerons une méthode de noyau quantique pour
- Une saisie matricielle à noyau unique pour des données comportant relativement peu de caractéristiques, à l'aide d'un véritable backend, afin que nous puissions facilement suivre ce qui se passe à chaque étape.
- Un ensemble de données complet avec relativement peu de caractéristiques, utilisant un backend simulé, afin que nous puissions voir comment le flux de travail quantique se connecte aux méthodes classiques d'apprentissage automatique
- Entrée d'une matrice à noyau unique pour des données comportant de nombreuses caractéristiques, à l'aide d'un véritable ordinateur quantique. Nous n'estimerons pas une matrice de noyau entière pour un grand ensemble de données, afin de respecter le temps sur les ordinateurs quantiques IBM®.
# If you have not already, install scikit learn
#!pip install scikit-learnEntrée de matrice à noyau unique
Étape 1 : Mettre en correspondance les entrées classiques avec un problème quantique
Considérons tout d'abord un ensemble de données ne comportant que quelques caractéristiques, disons 10. L'ensemble des données peut être aussi grand que vous le souhaitez, puisque nous calculons les éléments de la matrice du noyau un par un. Nous avons besoin d'au moins deux points, nous commencerons donc par cela (dans l'exemple suivant, nous importerons un ensemble de données complet). Importons quelques paquets nécessaires :
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# Two mock data points, including category labels, as in training
small_data = [
[-0.194, 0.114, -0.006, 0.301, -0.359, -0.088, -0.156, 0.342, -0.016, 0.143, 1],
[-0.1, 0.002, 0.244, 0.127, -0.064, -0.086, 0.072, 0.043, -0.053, 0.02, -1],
]
# Data points with labels removed, for inner product
train_data = [small_data[0][:-1], small_data[1][:-1]]Nous pouvons essayer d'utiliser le site z_feature_map.
# from qiskit.circuit.library import zz_feature_map
# fm = zz_feature_map(feature_dimension=np.shape(train_data)[1], entanglement='linear', reps=1)
from qiskit.circuit.library import z_feature_map
fm = z_feature_map(feature_dimension=np.shape(train_data)[1])
unitary1 = fm.assign_parameters(train_data[0])
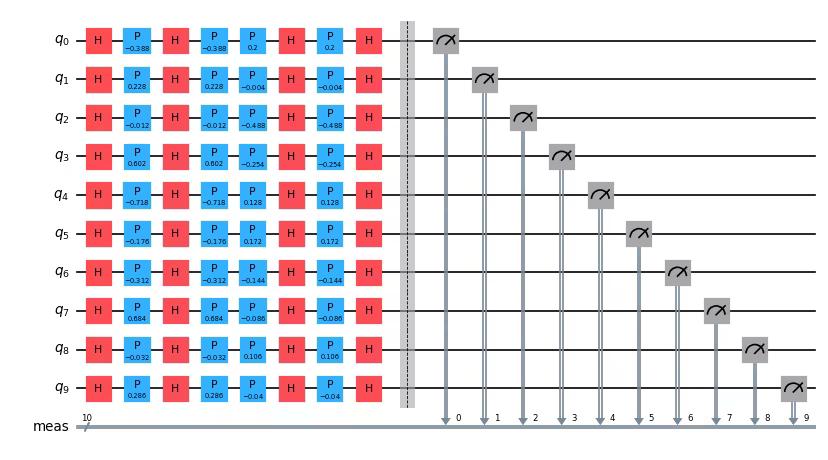
unitary2 = fm.assign_parameters(train_data[1])Les deux unitaires ci-dessus correspondent exactement à et décrits dans l'introduction. Nous pouvons les combiner en utilisant unitary_overlap. Comme toujours, nous voulons garder un œil sur la profondeur de notre circuit.
from qiskit.circuit.library import unitary_overlap
overlap_circ = unitary_overlap(unitary1, unitary2)
overlap_circ.measure_all()
print("circuit depth = ", overlap_circ.decompose().depth())
overlap_circ.decompose().draw("mpl", scale=0.6, style="iqp")Output:
circuit depth = 9
Étape 2 : Optimiser le problème pour l'exécution quantique
Nous commençons par sélectionner le backend le moins sollicité, puis nous optimisons notre circuit pour qu'il fonctionne sur ce backend.
# Import needed packages
from qiskit.transpiler.preset_passmanagers import generate_preset_pass_manager
from qiskit_ibm_runtime import QiskitRuntimeService
# Get the least busy backend
service = QiskitRuntimeService()
backend = service.least_busy(
operational=True, simulator=False, min_num_qubits=fm.num_qubits
)
print(backend)Output:
<IBMBackend('ibm_brisbane')>
# Apply level 3 optimization to our overlap circuit
pm = generate_preset_pass_manager(optimization_level=3, backend=backend)
overlap_ibm = pm.run(overlap_circ)Pour les circuits complexes, cette étape augmentera considérablement la profondeur du circuit, car elle correspond aux portes natives des ordinateurs quantiques réels, et l'information peut devoir être déplacée d'un qubit à l'autre. Dans ce cas simple, la profondeur est à peine affectée.
print("circuit depth = ", overlap_ibm.decompose().depth())
overlap_ibm.decompose().depth(lambda instr: len(instr.qubits) > 1)Output:
circuit depth = 10
1
Étape 3 : Exécuter à l'aide des primitives d' Qiskit Runtime
La syntaxe pour l'exécution sur un simulateur est commentée ci-dessous. Pour cet ensemble de données, avec un petit nombre de caractéristiques, l'exécution sur un simulateur reste une option. Pour les calculs à l'échelle des services publics, la simulation n'est généralement pas possible. Les simulateurs ne doivent être utilisés que pour déboguer un code réduit.
# Run this for a simulator
# from qiskit.primitives import StatevectorSampler
# from qiskit_ibm_runtime import Options, Session, Sampler
# num_shots = 10000
# Evaluate the problem using state vector-based primitives from Qiskit
# sampler = StatevectorSampler()
# results = sampler.run([overlap_circ], shots=num_shots).result()
# .get_counts() returns counts associated with a state labeled by bit results
# such as |001101...01>.
# counts_bit = results[0].data.meas.get_counts()
# .get_int_counts returns the same counts, but labeled by integer equivalent
# of the above bit string.
# counts = results[0].data.meas.get_int_counts()# Benchmarked on an Eagle processor, 7-11-24, took 4 sec.
# Import our runtime primitive
from qiskit_ibm_runtime import Session, SamplerV2 as Sampler
num_shots = 10000
# Use sampler and get the counts
sampler = Sampler(mode=backend)
results = sampler.run([overlap_ibm], shots=num_shots).result()
# .get_counts() returns counts associated with a state labeled by bit results such as |001101...01>.
counts_bit = results[0].data.meas.get_counts()
# .get_int_counts returns the same counts, but labeled by integer equivalent
# of the above bit string.
counts = results[0].data.meas.get_int_counts()Étape 4 : Post-traitement, renvoi du résultat dans un format classique
Comme décrit dans l'introduction, la mesure la plus utile ici est la probabilité de mesurer l'état zéro .
counts.get(0, 0.0) / num_shotsOutput:
0.6525
C'est le résultat que nous voulions : une estimation du produit intérieur (jusqu'au mod carré) des vecteurs correspondant à deux points de données. Si nous voulons examiner la distribution complète des probabilités de mesure (ou quasiprobabilités), nous pouvons le faire en utilisant la fonction plot_distribution comme indiqué ci-dessous. On constate que pour un grand nombre de qubits, les images de ce type deviennent rapidement irréalisables.
from qiskit.visualization import plot_distribution
plot_distribution(counts_bit)Output:
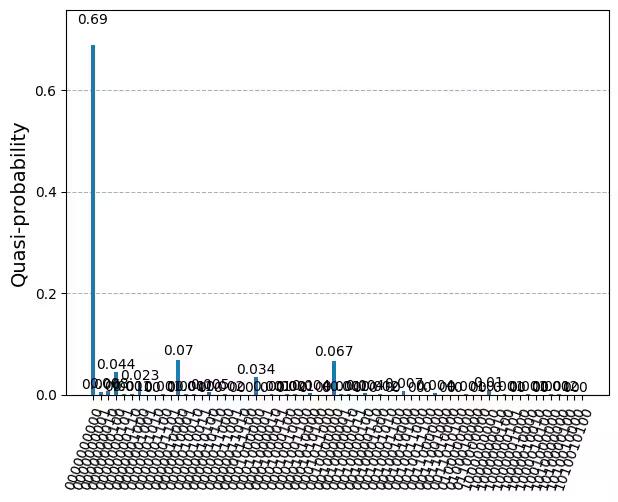
Il est également possible de définir une visualisation telle que celle présentée ci-dessous afin de n'examiner que les 10 mesures les plus probables. Cela peut s'avérer important pour le dépannage ou pour tenter d'obtenir plus d'intuition sur les données. Mais la probabilité de mesure de l'état zéro est l'élément de notre matrice noyau.
def visualize_counts(probs, num_qubits):
"""Visualize the outputs from the Qiskit Sampler primitive."""
zero_prob = probs.get(0, 0.0)
top_10 = dict(sorted(probs.items(), key=lambda item: item[1], reverse=True)[:10])
top_10.update({0: zero_prob})
by_key = dict(sorted(top_10.items(), key=lambda item: item[0]))
xvals, yvals = list(zip(*by_key.items()))
xvals = [bin(xval)[2:].zfill(num_qubits) for xval in xvals]
plt.bar(xvals, yvals)
plt.xticks(rotation=75)
plt.title("Results of sampling")
plt.xlabel("Measured bitstring")
plt.ylabel("Counts")
plt.show()
visualize_counts(counts, overlap_circ.num_qubits)Output:
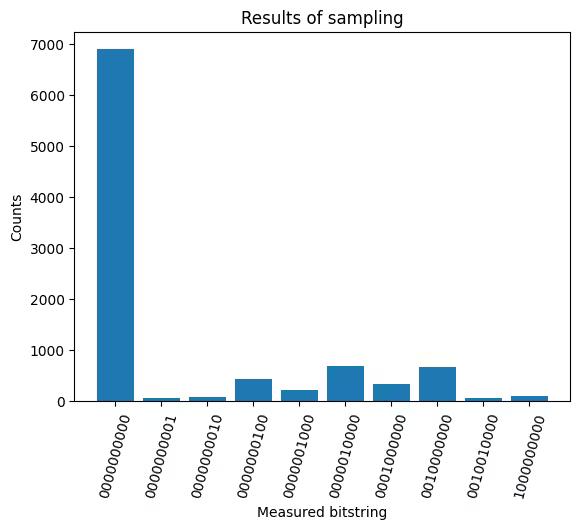
À partir de cette information concernant un seul produit intérieur entre deux points de données dans l'espace de caractéristiques de dimension supérieure, tout ce que nous pouvons dire est que leur chevauchement est relativement important par rapport au chevauchement maximal (qui serait de 1.0 ). Cela pourrait indiquer que ces deux points de données sont de nature similaire et qu'ils seront classés dans les mêmes classes. Il peut aussi s'agir d'un indicateur que notre carte des caractéristiques n'est pas efficace pour établir une correspondance dans un espace où les données similaires se chevauchent fortement et les données différentes se chevauchent faiblement. Pour savoir ce qui est vrai, nous devons appliquer notre carte de caractéristiques à l'ensemble des données et voir si la matrice du noyau qui en résulte peut être manipulée pour séparer efficacement les classes avec une grande précision.
Il convient de noter que nous avons utilisé le site z_feature_map qui a permis d'obtenir une faible profondeur de transposition à deux qubits (profondeur 1, en fait). Si vos circuits deviennent trop profonds, il en résultera certainement beaucoup de bruit, ce qui rendra la probabilité de mesurer l'état zéro très faible, même si votre carte de caractéristiques est bien adaptée à vos données. Par exemple, si l'on répète le processus ci-dessus en utilisant zz_feature_map et , entanglement='linear', reps=1 , on obtient dist.get(0,0.0) = 0.0015 en utilisant les mêmes points de données. Ceci est dû aux profondeurs de circuit et aux profondeurs de deux qubits beaucoup plus importantes à partir de zz_feature_map. La figure ci-dessous montre la distribution de probabilité pour ce calcul.
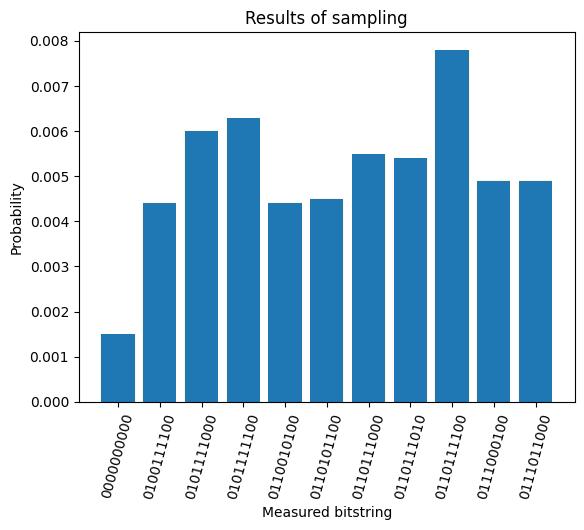
Il vaut la peine de jouer avec quelques points de données de la même catégorie pour voir à quel point la profondeur doit être faible pour obtenir de bons résultats. Ce qui suit est un conseil approximatif qui ne manquera pas de souffrir d'exceptions. En règle générale, une profondeur transpilée de 10 qubits ou moins ne devrait pas poser de problème. Une profondeur transpilée de 50 à 60 qubits est à la pointe de la technologie et nécessitera, entre autres, des outils avancés d'atténuation des erreurs. Entre les deux, vos résultats peuvent varier en fonction de la similarité des données, de l'expressivité de la carte des caractéristiques, de la largeur du circuit et d'autres facteurs.
En règle générale, l'étape de post-traitement comprend également des processus classiques d'apprentissage automatique. Dans la section suivante, nous étendrons ce processus à un ensemble de données complet et montrerons le processus classique d'apprentissage automatique.
Vérifiez votre compréhension
Dans un circuit quantique de 10 qubits, en général, combien d'états différents peuvent être mesurés?
ou 1024.
Imaginons qu'une personne novice en informatique quantique tente d'utiliser un circuit quantique présentant une profondeur à deux qubits très élevée, sans recourir à l'atténuation des erreurs. Supposons en outre que cela se traduise par un taux d'erreur de 10 % sur chaque qubit. Si l'élément de matrice du noyau réel (sans erreur) correspondant à ce circuit est très grand, disons de l'ordre de 1.0, quelle serait la probabilité de mesurer les 10 qubits comme étant tous dans l'état où chaque qubit est à l' ?
La probabilité que chaque qubit soit correctement trouvé dans l'état |0> est 0.90. La probabilité que les 10 qubits soient trouvés dans le bon état est de , soit environ 35 %.
Expliquez avec vos propres mots pourquoi il est si important de contrôler la profondeur des circuits. C'est vrai en général, mais expliquons-le dans le contexte de l'estimation quantique du noyau.
Dans ce flux de travail QKE, nos estimations sont basées sur les mesures de l'état zéro, c'est-à-dire l'état dans lequel chaque qubit se trouve à l'état . Les circuits très profonds introduisent des taux d'erreur élevés. Lorsque ce taux d'erreur est cumulé sur de nombreux qubits, la probabilité de mesurer l'état zéro s'en trouve considérablement réduite.
Matrice complète du noyau
Dans cette section, nous étendrons le processus ci-dessus à la classification binaire d'un ensemble complet de données. Cela introduira deux éléments importants : (1) nous pouvons maintenant mettre en œuvre l'apprentissage automatique classique en post-traitement et (2) nous pouvons obtenir des scores de précision pour notre formation.
Étape 1 : Mettre en correspondance les entrées classiques avec un problème quantique
Nous allons maintenant importer un jeu de données existant pour notre classification. Cet ensemble de données se compose de 128 lignes (points de données) et de 14 caractéristiques pour chaque point. Un quinzième élément indique la catégorie binaire de chaque point ( ). L'ensemble de données est importé ci-dessous, ou vous pouvez accéder à l'ensemble de données et voir sa structure ici.
Nous utiliserons les 90 premiers points de données pour la formation et les 30 points suivants pour les tests.
!wget https://raw.githubusercontent.com/qiskit-community/prototype-quantum-kernel-training/main/data/dataset_graph7.csv
df = pd.read_csv("dataset_graph7.csv", sep=",", header=None)
# Prepare training data
train_size = 90
X_train = df.values[0:train_size, :-1]
train_labels = df.values[0:train_size, -1]
# Prepare testing data
test_size = 30
X_test = df.values[train_size : train_size + test_size, :-1]
test_labels = df.values[train_size : train_size + test_size, -1]Output:
--2024-07-11 23:05:22-- https://raw.githubusercontent.com/qiskit-community/prototype-quantum-kernel-training/main/data/dataset_graph7.csv
Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 185.199.110.133, 185.199.111.133, 185.199.109.133, ...
Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|185.199.110.133|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 49405 (48K) [text/plain]
Saving to: ‘dataset_graph7.csv.15’
dataset_graph7.csv. 100%[===================>] 48.25K --.-KB/s in 0.02s
2024-07-11 23:05:23 (2.11 MB/s) - ‘dataset_graph7.csv.15’ saved [49405/49405]
Nous nous préparons déjà à stocker des résultats multiples en construisant une matrice noyau et une matrice test de dimensions appropriées.
# Empty kernel matrix
num_samples = np.shape(X_train)[0]
kernel_matrix = np.full((num_samples, num_samples), np.nan)
test_matrix = np.full((test_size, num_samples), np.nan)Nous créons maintenant une carte de caractéristiques pour encoder et cartographier nos données classiques dans un circuit quantique. Nous sommes libres de construire notre propre carte ou d'en utiliser une préfabriquée. N'hésitez pas à modifier la carte des fonctionnalités ci-dessous ou à revenir à ZFeatureMap. Mais il faut toujours faire attention à la profondeur du circuit. Rappelons que dans l'exemple précédent de 6 qubits, la profondeur du circuit transpilé était intraitablement élevée lorsque l'on utilisait zz_feature_map. Au fur et à mesure que l'échelle et la complexité du circuit augmentent, la profondeur peut rapidement augmenter jusqu'à un point où le bruit écrase nos résultats. Lorsque vous avez des connaissances sur la structure de vos données qui peuvent vous aider à déterminer la structure de la carte des caractéristiques la plus utile, il est conseillé de créer votre propre carte des caractéristiques personnalisée qui tire parti de ces connaissances.
from qiskit.circuit import Parameter, ParameterVector, QuantumCircuit
# Prepare feature map for computing overlap
num_features = np.shape(X_train)[1]
num_qubits = int(num_features / 2)
# To use a custom feature map use the lines below.
entangler_map = [[0, 2], [3, 4], [2, 5], [1, 4], [2, 3], [4, 6]]
fm = QuantumCircuit(num_qubits)
training_param = Parameter("θ")
feature_params = ParameterVector("x", num_qubits * 2)
fm.ry(training_param, fm.qubits)
for cz in entangler_map:
fm.cz(cz[0], cz[1])
for i in range(num_qubits):
fm.rz(-2 * feature_params[2 * i + 1], i)
fm.rx(-2 * feature_params[2 * i], i)Étapes 2 et 3 : Optimiser le problème et l'exécuter à l'aide de primitives
Nous construirons un circuit de chevauchement et, si nous utilisions un véritable ordinateur quantique dans cet exemple, nous l'optimiserions pour l'exécution comme précédemment. Mais dans ce cas, nous avons l'intention de passer en revue tous les points de données et de calculer la matrice du noyau complet. Pour chaque paire de vecteurs de données et , nous créons un circuit de chevauchement différent. Nous devons donc optimiser notre circuit pour chaque paire de points de données. Les étapes 2 et 3 seront donc réalisées ensemble lors des multiples itérations.
La cellule de code ci-dessous effectue exactement le même processus que précédemment pour une paire de points de données unique. Cette fois, il est simplement exécuté à l'intérieur de deux boucles for , et il y a une ligne supplémentaire à la fin kernel_matrix[x_1,x_2] = ... pour stocker les résultats de chaque calcul. Notez que nous avons tiré parti de la symétrie d'une matrice noyau pour réduire le nombre de calculs de 1/2. Nous avons également simplement fixé les éléments diagonaux à 1, comme ils devraient l'être en l'absence de bruit. En fonction de votre mise en œuvre et de la précision requise, vous pouvez également utiliser les éléments diagonaux pour estimer le bruit ou en prendre connaissance à des fins d'atténuation des erreurs.
Une fois que la matrice du noyau a été entièrement remplie, nous répétons le processus pour les données de test et nous remplissons la matrice du test. Il s'agit également d'une matrice à noyau; nous lui donnons simplement un nom différent pour la distinguer.
# To use a simulator
from qiskit.primitives import StatevectorSampler
# Remember to insert your token in the QiskitRuntimeService constructor
# to use real quantum computers
# service = QiskitRuntimeService()
# backend = service.least_busy(
# operational=True, simulator=False, min_num_qubits=fm.num_qubits
# )
num_shots = 10000
# Evaluate the problem using state vector-based primitives from Qiskit.
sampler = StatevectorSampler()
for x1 in range(0, train_size):
for x2 in range(x1 + 1, train_size):
unitary1 = fm.assign_parameters(list(X_train[x1]) + [np.pi / 2])
unitary2 = fm.assign_parameters(list(X_train[x2]) + [np.pi / 2])
# Create the overlap circuit
overlap_circ = unitary_overlap(unitary1, unitary2)
overlap_circ.measure_all()
# These lines run the qiskit sampler primitive.
counts = (
sampler.run([overlap_circ], shots=num_shots)
.result()[0]
.data.meas.get_int_counts()
)
# Assign the probability of the 0 state to the kernel matrix, and the transposed element
# (since this is an inner product)
kernel_matrix[x1, x2] = counts.get(0, 0.0) / num_shots
kernel_matrix[x2, x1] = counts.get(0, 0.0) / num_shots
# Fill in on-diagonal elements with 1, again, since this is an inner-product corresponding to
# probability (or alter the code to check these entries and verify they yield 1)
kernel_matrix[x1, x1] = 1
print("training done")
# Similar process to above, but for testing data.
for x1 in range(0, test_size):
for x2 in range(0, train_size):
unitary1 = fm.assign_parameters(list(X_test[x1]) + [np.pi / 2])
unitary2 = fm.assign_parameters(list(X_train[x2]) + [np.pi / 2])
# Create the overlap circuit
overlap_circ = unitary_overlap(unitary1, unitary2)
overlap_circ.measure_all()
counts = (
sampler.run([overlap_circ], shots=num_shots)
.result()[0]
.data.meas.get_int_counts()
)
test_matrix[x1, x2] = counts.get(0, 0.0) / num_shots
print("test matrix done")Output:
training done
test matrix done
Étape 4 : Post-traitement, renvoi du résultat dans un format classique
Maintenant que nous disposons d'une matrice de noyau et d'une matrice de test au format similaire pour les méthodes de noyau quantique, nous pouvons appliquer des algorithmes classiques d'apprentissage automatique pour faire des prédictions sur nos données de test et vérifier leur exactitude. Nous commencerons par importer sklearn.svc de Scikit-Learn, un classificateur à vecteur de support (SVC). Nous devons spécifier que nous voulons que le SVC utilise notre noyau précalculé en utilisant kernel = precomputed.
# import a support vector classifier from a classical ML package.
from sklearn.svm import SVC
# Specify that you want to use a pre-computed kernel matrix
qml_svc = SVC(kernel="precomputed")À l'aide de SVC.fit, nous pouvons maintenant introduire la matrice du noyau et les étiquettes d'apprentissage pour obtenir un ajustement. SVC.score évaluera alors nos données de test par rapport à cet ajustement à l'aide de notre matrice test, et renverra notre précision.
# Feed in the pre-computed matrix and the labels of the training data.
# The classical algorithm gives you a fit.
qml_svc.fit(kernel_matrix, train_labels)
# Now use the .score to test your data, using the matrix of test data,
# and test labels as your inputs.
qml_score_precomputed_kernel = qml_svc.score(test_matrix, test_labels)
print(f"Precomputed kernel classification test score: {qml_score_precomputed_kernel}")Output:
Precomputed kernel classification test score: 1.0
Nous constatons que la précision de notre modèle formé est de 100 %. C'est une excellente chose et cela montre que le QKE peut fonctionner. Mais cela est très différent de l'avantage quantique. Les noyaux classiques auraient probablement été en mesure de résoudre ce problème de classification avec une précision de 100 %. Il reste encore beaucoup à faire pour caractériser les différents types de données et les relations entre les données afin de déterminer où les noyaux quantiques seront les plus utiles dans l'ère actuelle des services publics. Nous laissons à l'apprenant le soin de modifier certaines parties de ce processus et d'étudier l'efficacité de diverses cartes de caractéristiques quantiques. Voici quelques éléments à prendre en compte :
- Quelle est la fiabilité de la précision? Cela vaut-il pour de vastes types de données ou uniquement pour ces données de formation spécifiques?
- Quelle structure de vos données vous fait penser qu'une carte de caractéristiques quantiques est utile?
- Comment la précision est-elle affectée par l'augmentation ou la diminution de la quantité de données d'apprentissage?
- Quelles cartes caractéristiques pouvez-vous utiliser et comment les résultats varient-ils en fonction des cartes caractéristiques?
- Comment la précision et la durée d'exécution sont-elles affectées par l'augmentation du nombre de caractéristiques?
- Quelles sont les tendances, s'il y en a, qui se maintiendront sur les ordinateurs quantiques réels?
Évolutivité vers davantage de fonctionnalités et de qubits
Dans cette section, nous répétons le calcul d'un seul élément de la matrice, mais pour un nombre beaucoup plus important de caractéristiques, en esquissant le chemin de l'échelle vers l'utilité. La restriction à un seul élément de la matrice a pour but de montrer le processus sans utiliser trop de temps sur les ordinateurs quantiques.
Étape 1 : Mettre en correspondance les entrées classiques avec un problème quantique
Nous partons d'un ensemble de données dans lequel chaque point de données comporte 42 caractéristiques. Comme dans le premier exemple, nous calculerons un seul élément de la matrice du noyau, nécessitant deux points de données. Les deux points ci-dessous ont 42 caractéristiques et une seule variable de catégorie ( ).
# Two mock data points, including category labels, as in training
large_data = [
[
-0.028,
-1.49,
-1.698,
0.107,
-1.536,
-1.538,
-1.356,
-1.514,
-0.109,
-1.8,
-0.122,
-1.651,
-1.955,
-0.123,
-1.732,
0.091,
-0.048,
-0.128,
-0.026,
0.082,
-1.263,
0.065,
0.004,
-0.055,
-0.08,
-0.173,
-1.734,
-0.39,
-1.451,
0.078,
-1.578,
-0.025,
-0.184,
-0.119,
-1.336,
0.055,
-0.204,
-1.578,
0.132,
-0.121,
-1.599,
-0.187,
-1,
],
[
-1.414,
-1.439,
-1.606,
0.246,
-1.673,
0.002,
-1.317,
-1.262,
-0.178,
-1.814,
0.013,
-1.619,
-1.86,
-0.25,
-0.212,
-0.214,
-0.033,
0.071,
-0.11,
-1.607,
0.441,
-0.143,
-0.009,
-1.655,
-1.579,
0.381,
-1.86,
-0.079,
-0.088,
-0.058,
-1.481,
-0.064,
-0.065,
-1.507,
0.177,
-0.131,
-0.153,
0.07,
-1.627,
0.593,
-1.547,
-0.16,
-1,
],
]
train_data = [large_data[0][:-1], large_data[1][:-1]]Rappelons que le site zz_feature_map a produit des circuits assez profonds dans le cas de caractéristiques relativement peu nombreuses (14 caractéristiques). Au fur et à mesure que nous augmentons le nombre de fonctionnalités, nous devons surveiller de près la profondeur du circuit. Pour illustrer cela, nous allons d'abord essayer d'utiliser le site zz_feature_map et vérifier la profondeur du circuit résultant.
from qiskit.circuit.library import zz_feature_map
fm = zz_feature_map(
feature_dimension=np.shape(train_data)[1], entanglement="linear", reps=1
)
unitary1 = fm.assign_parameters(train_data[0])
unitary2 = fm.assign_parameters(train_data[1])from qiskit.circuit.library import unitary_overlap
overlap_circ = unitary_overlap(unitary1, unitary2)
overlap_circ.measure_all()
print("circuit depth = ", overlap_circ.decompose(reps=2).depth())
print(
"two-qubit depth",
overlap_circ.decompose().depth(lambda instr: len(instr.qubits) > 1),
)
# overlap_circ.draw("mpl", scale=0.6, style="iqp")Output:
circuit depth = 251
two-qubit depth 165
Comme nous l'avons vu précédemment, il est difficile de déterminer la profondeur exacte de ce qui est trop profond. Mais une profondeur de deux qubits supérieure à 100, même avant la transpilation, n'est pas envisageable. C'est pourquoi l'accent a été mis sur les cartes d'entités personnalisées tout au long de cette leçon. Si vous connaissez la structure de l'ensemble de vos données, vous devez concevoir une carte d'intrication en tenant compte de cette structure. Ici, comme nous ne calculons que le produit intérieur entre deux points de données de ce type, nous avons donné la priorité à une faible profondeur de circuit plutôt qu'à un examen détaillé de la structure des données.
from qiskit.circuit import Parameter, ParameterVector, QuantumCircuit
# Prepare feature map for computing overlap
entangler_map = [
[3, 4],
[2, 5],
[1, 4],
[2, 3],
[4, 6],
[7, 9],
[10, 11],
[9, 12],
[8, 11],
[9, 10],
[11, 13],
[14, 16],
[17, 18],
[16, 19],
[15, 18],
[16, 17],
[18, 20],
]# Use the entangler map above to build a feature map
num_features = np.shape(train_data)[1]
num_qubits = int(num_features / 2)
fm = QuantumCircuit(num_qubits)
training_param = Parameter("θ")
feature_params = ParameterVector("x", num_qubits * 2)
fm.ry(training_param, fm.qubits)
for cz in entangler_map:
fm.cz(cz[0], cz[1])
for i in range(num_qubits):
fm.rz(-2 * feature_params[2 * i + 1], i)
fm.rx(-2 * feature_params[2 * i], i)from qiskit.circuit.library import unitary_overlap
# Assign features of each data point to a unitary, an instance of the general feature map.
unitary1 = fm.assign_parameters(list(train_data[0]) + [np.pi / 2])
unitary2 = fm.assign_parameters(list(train_data[1]) + [np.pi / 2])
# Create the overlap circuit
overlap_circ = unitary_overlap(unitary1, unitary2)
overlap_circ.measure_all()Nous ne prendrons pas la peine de vérifier les profondeurs pour l'instant, puisque ce qui importe vraiment est la profondeur de deux qubits transposée.
Étape 2 : Optimiser le problème pour l'exécution quantique
Nous commençons par sélectionner le backend le moins sollicité, puis nous optimisons notre circuit pour qu'il fonctionne sur ce backend.
# Import needed packages
from qiskit.transpiler.preset_passmanagers import generate_preset_pass_manager
from qiskit_ibm_runtime import QiskitRuntimeService
# Get the least busy backend
service = QiskitRuntimeService()
backend = service.least_busy(
operational=True, simulator=False, min_num_qubits=fm.num_qubits
)
print(backend)Output:
<IBMBackend('ibm_brisbane')>
Pour les petits travaux, un gestionnaire de passage prédéfini permet souvent de renvoyer le même circuit avec la même profondeur, de manière fiable. Mais dans les circuits complexes de très grande taille, le gestionnaire de passage peut renvoyer des circuits transpilés différents à chaque fois qu'il s'exécute. Cela s'explique par l'utilisation d'heuristiques et par le fait que les très grands circuits présentent un paysage complexe d'optimisations possibles. Il est souvent utile de transpiler plusieurs fois et de prendre le circuit le moins profond. Cela n'introduit qu'un surcoût classique et peut améliorer considérablement les résultats de l'ordinateur quantique.
Ici, nous transposons 20 fois le circuit de chevauchement unitaire et examinons les profondeurs des circuits obtenus.
# Apply level 3 optimization to our overlap circuit
transpiled_qcs = []
transpiled_depths = []
transpiled_twoqubit_depths = []
for i in range(1, 20):
pm = generate_preset_pass_manager(optimization_level=3, backend=backend)
overlap_ibm = pm.run(overlap_circ)
transpiled_qcs.append(overlap_ibm)
transpiled_depths.append(overlap_ibm.decompose().depth())
transpiled_twoqubit_depths.append(
overlap_ibm.decompose().depth(lambda instr: len(instr.qubits) > 1)
)
print("circuit depth = ", overlap_ibm.decompose().depth())Output:
circuit depth = 61
print(transpiled_depths)
print(transpiled_twoqubit_depths)Output:
[61, 60, 60, 69, 60, 60, 60, 65, 60, 60, 69, 61, 77, 77, 65, 60, 60, 77, 61]
[13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13]
Ici, vous pouvez voir qu'il y a une certaine variation dans la profondeur totale de la porte avec différentes passes de transpilation. Notre circuit n'est pas encore assez profond/étendu pour voir des variations dans les profondeurs transposées de deux qubits. Nous utiliserons le site transpiled_qcs[1], qui a une profondeur de 60, à peine inférieure à la profondeur du circuit le plus profond obtenu, qui était de 77.
overlap_ibm = transpiled_qcs[1]Étape 3 : Exécuter à l'aide des primitives d' Qiskit Runtime
Au fur et à mesure que nous nous rapprochons de l'utilité, les simulateurs ne seront plus utiles. Seule la syntaxe des véritables ordinateurs quantiques est présentée ici.
# Run on ibm_osaka, 7-12-24, required 22 sec.
# Import our runtime primitive
from qiskit_ibm_runtime import SamplerV2 as Sampler
# Open a Runtime session:
session = Session(backend=backend)
num_shots = 10000
# Use sampler and get the counts
sampler = Sampler(mode=session)
options = sampler.options
options.dynamical_decoupling.enable = True
options.twirling.enable_gates = True
counts = (
sampler.run([overlap_ibm], shots=num_shots).result()[0].data.meas.get_int_counts()
)
# Close session after done
session.close()Étape 4 : Post-traitement, renvoi du résultat dans un format classique
Comme décrit dans l'introduction, la mesure la plus utile ici est la probabilité de mesurer l'état zéro .
counts.get(0, 0.0) / num_shotsOutput:
0.0138
Ce processus pour l'élément unique de la matrice du noyau peut être répété entre d'autres paires de données dans votre ensemble pour obtenir la matrice du noyau complète. La dimension de la matrice du noyau est déterminée par le nombre de points dans vos données d'apprentissage, et non par le nombre de caractéristiques. Ainsi, le coût informatique de la manipulation de la matrice du noyau dans un modèle prédictif ne varie pas en fonction du nombre de caractéristiques ou de qubits. Même pour des ensembles de données relativement petits comportant un grand nombre de caractéristiques, les données doivent encore être mises en correspondance avec une carte de caractéristiques permettant d'obtenir une classification efficace.
Évolutivité et travaux futurs
La méthode du noyau exige que nous mesurions l'adresse avec la plus grande précision possible. Mais les erreurs de porte et les erreurs de lecture signifient qu'il existe une probabilité non nulle qu'un qubit donné soit mesuré par erreur comme étant dans l'état . Même en simplifiant à l'extrême que la probabilité de devrait être , pour de nombreuses caractéristiques codées sur, disons, bits, la probabilité de mesurer correctement tous les bits pour être est réduite à . Au fur et à mesure que devient important, cette méthode devient de moins en moins fiable. La recherche actuelle vise à surmonter cette difficulté et à étendre l'estimation du noyau à un nombre croissant de caractéristiques. Pour en savoir plus sur cette question, voir le travail de Thanasilp, Wang, Cerezo et Holmes Nous vous recommandons d'explorer ce qui peut être fait avec les ordinateurs quantiques actuels et d'envisager ce qui sera possible à l'ère de la correction d'erreurs.
Réviser
Le calcul d'un noyau quantique implique
- calcul des entrées de la matrice du noyau, en utilisant des paires de points de données d'apprentissage
- codage des données et mise en correspondance par le biais d'une mise en correspondance des caractéristiques
- optimiser votre circuit pour qu'il fonctionne sur des ordinateurs quantiques réels / des backends
Le noyau quantique peut ensuite être utilisé dans des algorithmes classiques d'apprentissage automatique, comme dans cette leçon.
Voici quelques points essentiels à garder à l'esprit lors de l'utilisation de noyaux quantiques :
- L'ensemble de données est-il susceptible de bénéficier des méthodes du noyau quantique?
- Essayez différentes cartes de caractéristiques et différents schémas d'enchevêtrement.
- La profondeur du circuit est-elle acceptable?
- Essayez de faire fonctionner un gestionnaire de passage plusieurs fois et utilisez le circuit le moins profond possible.
Les méthodes à noyau quantique sont des outils potentiellement puissants si l'on dispose d'une correspondance adéquate entre les ensembles de données avec des caractéristiques quantiques et d'une carte de caractéristiques quantiques appropriée. Pour mieux comprendre où les noyaux quantiques sont susceptibles d'être utiles, nous recommandons la lecture de Liu, Arunachalam & Temme (2021).